Stop me if you’ve heard this one before …
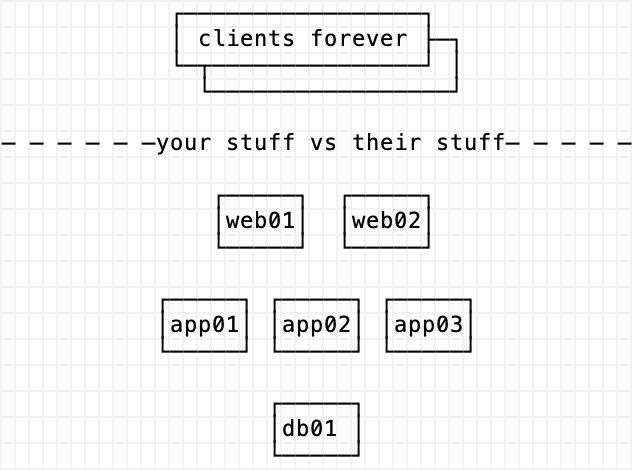
Here is a three tier web stack. It has lots of web and app servers but only one database box. You can substitute this with cloud things but the principles are the same. I bet your infrastructure looks really similar. For the remainder of the post, assume I mean a traditional RDMS when I say database.
Why is there always only db01? Your box might be called prod-db1 or mysql-01. You know the one I mean. Maybe you have a db02 but I bet it’s running in a special mode. Db02 is another exception to the rule (maybe a read-only replica for reporting). Whatever the case, I bet there’s only one db01 but there are so many of the other things. Why?
We can summarize scaling each tier in this whole stack like this:
- clients: not our problem, there’s millions of them
- web tier: easy-peasy, it’s a daemon plus a config file
- app tier: it’s our code / stuff; it’s in a load balancer pool even if it has state we have tricks to scale it
- database tier: don’t touch it! there can only be one!
Each tier is either easy to reason about scaling out horizontally except for the database. What is going on here? I’m going to go over a few good ideas and why they die on the database tier.
The Good Ideas
Let’s Load Balance
Load balancer pools work great for tiers without state. You can even use tricks like sticky sessions when you have some state. But the request is short. A database resists these ideas because connections are long and the entirety of state is local. You can’t put database volumes on a shared drive and expect it to work (well). So the problem is at least state but let’s keep chatting about some other ideas.
Let’s Dockerize
Docker works great for tiers without state. You can dockerize your database but you don’t get the scaling and uniformity advantages of the other tiers. Docker is great for production and deployment but you are not deploying your database that often without a lot of fancy uptime tooling. In addition, you have footguns with non-obvious behavior around volumes. You can do it but it’s the exception when the app and web tiers are so easy to explain and reason about.
There are few threads and debates about dockerizing the other tiers. Dockerizing the database layer can be debated and googled.
Let’s Go Active-Active
Horizontal scaling doesn’t work on the database tier. You can’t easily have a read/write (active) pair. There are alternate daemons and methods (NewSQL) but here I mean common relational SQL databases.
Let’s Do Immutable or Config Management
What about NixOS? Or some other hot and trendy new idea? My first concern and question when I heard about NixOS was about the database layer. I have asked this question about NixOS and apparently it’s ok to do so. However, I don’t completely grok this but I guess this is part of my point. The database tier is a special case again.
You definitely can’t do the cattle thing because you can’t have a load balancer. You can only do the cattle/pets thing in the app tier because you have a load balancer with a health check.
Let’s Mock I/O Seams
During unit testing you might want your tests not to hit an API. You can mock out the HTTP interface and test against a mock response (or even better, ignore the response entirely). This is basically mocking out someone else’s (or your own) app server. So why don’t people do this with the database? Is it because the response is so important? It’s more of a language and state engine than a simple message passing metaphor?
You can find fakeredis adapters in Python, fake caches in Ruby and in-memory databases in C#. But it’s all surrounded by caveats. It’s just easier to create a test database because databases ruin all good ideas. At least database tech enables a workaround.
There is so much state and back-and-forth protocol in a relational database that treating it like client/server message passing is too simple. All the state and data lives in the database. Even triggers and internals would be too complicated to account for. It’s just easier to create a test database because database namespaces/collections are very easy to create. Databases also have the advantage of rolling back in a transaction which works great for unit testing.
So your project might have fake adapters but not for mysql/postgres. Or maybe you use sqlite in dev/tests and something bigger in prod. But you don’t change entire products for your caches/queues based on the environment do you? See what I mean?
Let’s Use The Cloud
Renting large boxes usually doesn’t make sense financially. You’d be better off just buying. The same is true for performance clusters and GPUs. The scaling and pooling problems from above don’t change. Even a SaaS has the same issue. In this case the singular db01 box just moves to the cloud.
Let’s Keep It Simple with a Microframework
I really like the syntax and style of Labstack’s Echo framework for Golang. But my experience changed when adding a database to my app. The simplicity fell apart in that putting a global variable makes it hard to test. Without state, I don’t have this problem. There are many microframeworks where this happens. You can almost predict it happening if you look at the table of contents for the documentation and see that they have no database story.
Let’s Deploy Often with a Chatbot
We had a chatbot that had two endpoints for deployment: /deploy and /deploy-with-migrations. It worked well, we did deploys almost every day. I’m not saying that the database is unusable but this illustrates my point. The happy path of /deploy is naive. It was probably written first. And then you say “oops, I forgot about the database” and you have to write a special or more careful version to do database migrations.
A Horrible Story
Very long ago, I worked on an Oracle cluster that required a ton of specialized software, hardware, admin and configuration. Almost the entire idea was about availability and performance. The CEO just couldn’t stand the fact that half of the system is wasting money being read-only. He wanted read-write on both nodes. Active active. This was a long time ago but the CAP theorum isn’t going to change. I learned a ton about splitbrain mostly through trauma.
At the time, you couldn’t just download a relational database that will do horizontal scaling. You had to buy all these vendor options and stuff. It was super expensive. I forget the price, probably $40k for the db license and $20k for the clustering addon. And then you needed specialized disk and volume software. The hardware was really pricey too because it was Sun at the time.
During cluster install it tells you to plug in a crossover cable to a dedicated NIC. Like, you had eth1 just sitting there free or you had to buy a NIC for it. I think we bought a NIC. The install isn’t going to work unless you do this crossover thing. In addition, you need to set up a quorum disk on your SAN to act as a tiebreaker (more on that later). All the traffic over this crossover cable is SSH. All it’s doing is doing relational database agreement over SSH. There’s no data sharding or splitting you have to do so it’s all or nothing. Full-on ACID agreement, all the time. This is why you have a dedicated NIC because of network load.
So you finally beat the CAP theorum. You got your active-active database and you didn’t have to change your app at all. Now comes the trade off, the the devil’s details. ACID means we have to 100% agree on every query. That means, all nodes, all the time. This is why scaling nodes was so bad. You got about 50% on the second node and then +25% on the third node. It stopped scaling after 4. Remember, each node is incredibly expensive. Also, your nervous system is this crossover cable (actually a pair). What happens if I take some scissors to it?
Well, db01 thinks it’s up. And db02 thinks it’s up. But db02 thinks db01 is gone. And db01 thinks db02 is gone. So, now what? What happens if a write comes in to both db01 and db02?
db01: foo=bar
db02: foo=ohno
What’s foo supposed to be? s p l i t b r a i n
So this is why you configured a quorum disk. When the cluster looses quorum, there’s a race to the quorum disk. It writes a magic number to the start of the disk sector (not even like in the normal part of the disk iirc) and whoever arrives 2nd, panics on purpose. Now you have survived split brain. But you needed crazy shared disk technology to even do this for arbitrary reasons.
It was a crazy time and I should share this as production horror chops sometime later. A lot of the technology in this story is super old. But some of it hasn’t changed. When I learned Mongo, I had a high degree of context from this horror and I didn’t have to ask “yeah but why” a lot.
Way back when, our CEO couldn’t stand to have half the hardware sitting around doing nothing. He wanted it involved. It’s not like it’s a “dumb idea”. It was a good idea! A lot of people have good ideas around the database. To me though, databases ruin all good ideas. This is how I chunk it. I know it’s cute but it keeps coming up.