One of the hardest questions I’ve been asked is “how do I get production experience?”. Someone was looking for a job and they were seeing job requirements about production and operations. They didn’t have any. The landscape has changed quite a bit since I was a sysadmin but the Catch-22 is the same. The Catch-22 being: you can’t get ops experience without an ops job and you can’t get an ops job without ops experience. But I think the chicken-egg cycle can be broken. Let me explain what Scenario Practice is and offer some scenarios to practice.
For someone interested in in ops, the big idea I would communicate is: a server really isn’t that much different than your local shell. For early learning, this is really true. If you get better on a Linux shell through your raspberry pi / Mac / WSL terminal, it will directly translate to Linux server skills. If you make your main machine Linux, I promise you will learn Linux just from a purely survival standpoint. If you need to fullscreen a VM and do it with discipline instead of wiping your disk, do that. The point is to feel the necessity of fixing it yourself.
The difference between cat /proc/cpuinfo on a huge zillion-core server and a tiny raspberry pi is just the text output. The knowledge of what /proc is doesn’t change. But this sandboxing skill translation can’t scale to all problems. You probably don’t have access to expensive network switches, strange storage equipment, locked-in vendor tools or even OSS that has real-world complexity in it that you can’t recreate what would be at work without that knowledge already. Some areas (such as realistic production scenarios) are hard to sandbox on your laptop, home lab or in a personal space. But there’s still opportunity to learn things that do sandbox-translate.

So, making your main machine Linux, learning some shell skills and surviving might teach you sysadmin what about ops? This is trickier but I think it has to do with systems. The remainder of this post moves kind of fast and might sound a bit like Draw the Rest of the Owl because it’s encouraging building systems for the ops experience but skips over the OS/Linux/shell stuff. If you are stuck, you might have to research and work on that particular topic. Or maybe I’m not targetting the right audience. I’m sorry I don’t have repos and done demos to offer right now.
Scenario Practice
Scenario Practice is about setting up production scenarios to fight the catch-22 of ops experience. It’s probably useful for people already in ops too; ops folks that are curious, worried or want to practice these situations. I’m just going to describe some of the scenario ideas I’ve had, mostly ordered from simplest to most complicated. The situations mostly involve a developer/ops hybrid role. So if you are purely ops and I say to create an application, you might have to improvise or find an existing app (maybe todomvc but you need agency and control of this app to change it). The point here is to explain Scenario Practice, give it a name and perhaps inspire some things to practice.
The Mock Client
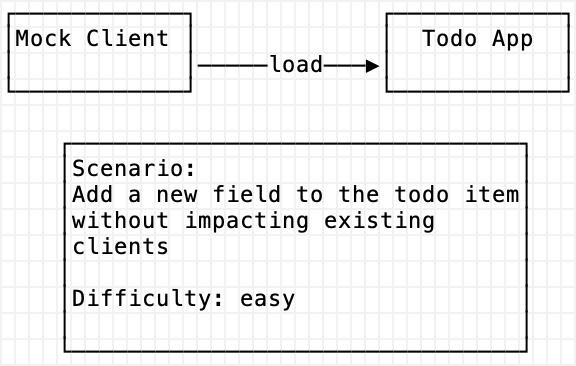
First, we need to have a mock client for simulating constant load and use. This client represents a user of the system. This user is a credit-card carrying, impatient type that would cost us money if we lose their request. This client is really important to be constantly running so we can experience failures and develop some feel. There are many ways to implement this mock client:
- You could write a shell while loop to call curl
- You could make an infinite looping HTTP client call in your language of choice
- You could use a load tester like
k6orsiege(for the scenarios that just deal with availability, a benchmarking tool like siege isn’t going to expose JSON problems)
It doesn’t matter too much. The important thing here is to make the client sensitive to the failure you are trying to avoid. If you have a shell loop every second then your failure mitigation cannot cheat by typing faster than a second where you survived a failure by luck alone. So, for each scenario I’m going to assume you have a mock client already running in another terminal.
For example, the solution to the above scenario is this:
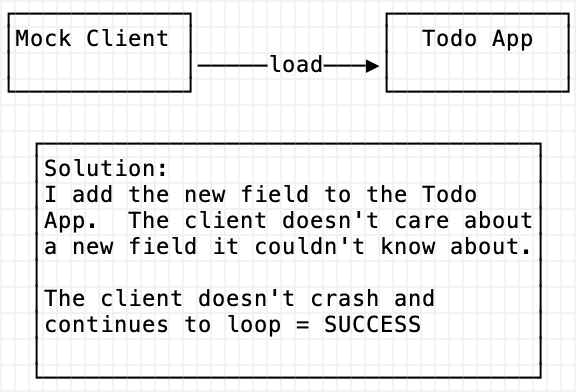
Section 1 - Three Tier Web Application Uptime
- Create a todo list database
- Create a middle tier JSON service to serve up the todo list
You can do this by hand, as quick as possible or use an app off todomvc.
Scenario A - single server
You have a single app server. It’s going to crash or need os updates. You don’t want your mock client to throw errors though.
The exercises for this would be:
- You turn off the app server as if you did os updates, would there be any way to avoid the outage? (spoiler: not really)
- If there was a major app update, could you roll it out smoothly? (spoiler: not really)
This is kind of a sanity test step. If you have your mock client hammering your app, when you stop your app your client should start throwing errors.
Scenario B - playing with the middle tier:
Building off of A, mitigate those outages by using a load balancer like HAProxy. Now you now have a load balancer and two app servers.
Exercise 1: Turn off the first app server and have your todo service still work. Exercise 2: Add a new app server and turn the first one back on (for a total of 3) and have your todo service still work.
Scenario C - using the middle tier to control change:
Change your app in a breaking way. If you have JSON that looks like this:
{
"todos": [
{ "name": "Get Milk", "completed": false },
{ "name": "Get Eggs", "completed": true }
]
}
Change the API so that it breaks clients. Here, we’re changing field names.
[
{ "title": "Get Milk", "done": false },
{ "title": "Get Eggs", "done": true }
]
If you are using a curl loop for your continuous load, you could pipe the JSON to jq where jq
specifically looks for the field name. When name changes to title, jq should break.
It doesn’t matter how much it changes but your mock client is going to have to simulate and represent a customer/user that doesn’t want to change but also a client that is changing. You could do a scenario where you have a cutover date but this is essentially downtime from a dev standpoint. Your service is up but from a business domain standpoint, your API has changed.
Exercise 1: Roll out the new API while supporting the old API and the new one. You could do this with headers, URL paths or an entirely different load balancer pool.
Exercise 2: Deprecate the old API. Monitor traffic. Change your stubborn old client to use the new API. Turn off the old API. This is mostly busy work and if you just want to think about how this would work, that’s fine.
Section 2 - Database State
Use the same three tier app from Section 1. In this part, I’m introducing a hard to solve problem with the database. Your challenge here is to move your database from mysql to postgres or vice-versa. Your todos are in one. You will create a new database machine (or just a process/port), whichever one you don’t currently have. For this example, I’ll say we started with mysql but substitute whichever one you have. The key here is to just create the initial data by hand. I would not make this too fancy unless your web framework, tools or experience lead you that way.
Exercise 1: Copy all the data you have as if writes don’t happen that much
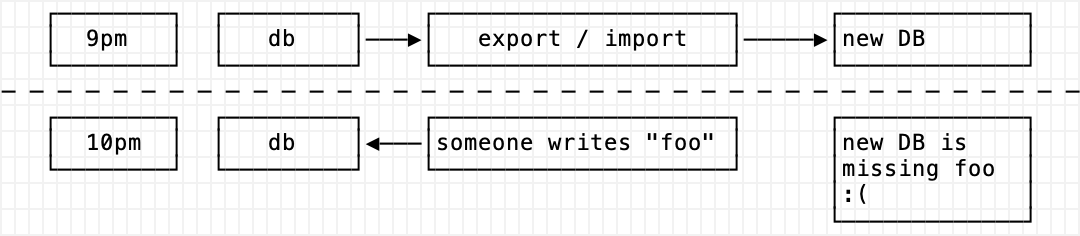
Maybe the todo lists don’t change that much. This is kind of unrealistic but maybe your app is read only (up to this point my examples have been implying that it is). Copy the data as if you did this late at night or during out an outage. This is probably dumping SQL and importing but it could also be a program you write with two database connections. The takeaway here is, this is not a great way to do things. You have to stop writes in order to make a database export. Unless you figure out a way to find all rows past a certain date?
Exercise 2: Introduce a write endpoint to your app
It lets someone add a new todo item. This could happen with curl or a client you write. Make it simple.
Now that you have a client that can add todo items, have your writing client loop and create dummy todo items. While your client is periodically and continuously adding random todo items, think about how you can change databases live. The new database could be a different database name in mysql or a different daemon entirely. This is pretty tricky to think about so I made a diagram.
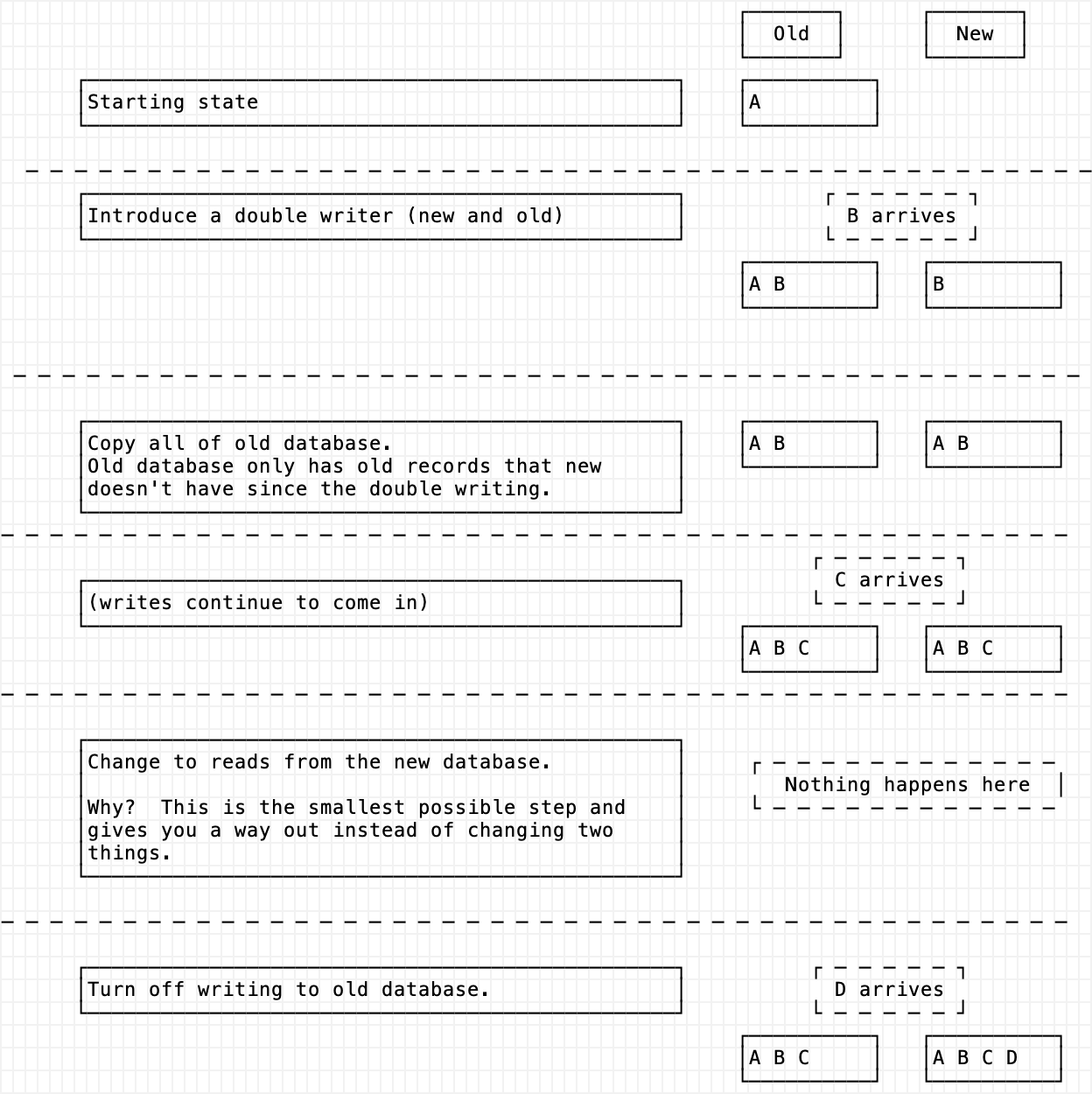
See if you can go through these steps while your client loops. The client shouldn’t error. When you are done, you can delete the old database. There still shouldn’t be an error.
Exercise 3: Switch back to whatever database your prefer (where Exercise 2 maybe changed your preference)
Add a new field called author. Your API might look like this now:
[
{ "name": "Get Milk", "completed": false, "author": "Jane Doe" },
{ "name": "Get Eggs", "completed": true, "author": "John Doe" }
]
This is the starting point for this exercise, not the thing to solve. The change is going to be to split this name into two parts. It turns out we want to filter by last name in our todo list app. The way you might approach this is to do many deploys and changes (remember your client needs to continue working from a network/service standpoint, but also this is a breaking API change like from Section 1/Scenario C1).
- Make a change to the database to add two new empty fields:
author_first_nameandauthor_last_name - Write a script or split the author by hand in the database. This is not critical. Now you have data in the database for author, author_first_name, author_last_name.
- Expose the new fields with the API.
[
{
"name": "Get Milk",
"completed": false,
"author": "Jane Doe",
"author_first_name": "Jane",
"author_last_name": "Doe"
},
{
"name": "Get Eggs",
"completed": true,
"author": "John Doe",
"author_first_name": "John",
"author_last_name": "Doe"
}
]
- This is the point where clients switch or you support two endpoints like Section 1/Scenario C1.
- Roll out a new app that does not expose the author field.
- Delete the author column in the database. So you can see there are many app deploys (and possibly scripts) to make this happen.
Rapid Fire Ideas
Hopefully I have illustrated what Scenario Practice is and given you some ideas. I’m going to throw out some other ideas really quickly without describing them in great detail.
- DNS tricks - practice hiding change behind DNS records and not IPs. There’s a fancier version of this with service discovery and/or with something like Consul from Hashicorp.
- Using compatible services in a similar way to the database changes. But instead of a relational database, start with Redis and use a tool from the google search redis protocol compatible. The idea here is moving to something similar, with some killer feature you need but not ruining everything.
- Using primaries and secondaries to simulate a massive problem. This could be read-only with a relational database, this could even be with redis. This could also be testing your backups.
- Async speedups. Some job queues are language agnostic or have many clients. Do you imagine that one day your javascript/python/ruby/php job workers might be too slow? Is there some computation-heavy thing? Could you use another language? Actually try it out! Make a worker in go/rust/crystal (something fast) and have it do some work. You expect it to be faster, right? Make sure to measure it and really know. Warning: this might put you into micro-benchmark lie territory.
- Handling multiple clients. You can try a lot of different things here. If you have different branches deployed at different endpoints handling different clients, there’s a lot of room for improvement. You could stick with what you have and try tracking the endpoints, simulating ever increasing complexity. You could also set up this complicated scenario and trying GraphQL or some other approach.
- Keeping multiple clients working with contract testing. Use Pact (pact.io) to keep your clients working. Just like previous scenarios where you have client load giving you feedback, you can use contract tests to prevent that breakage but also a real client making sure that Pact isn’t lying to you. If you don’t like pact or contract tests, do the same thing with swagger (or openapi). Swagger has client generation which is what couples your API to code as sort of enforcment.
- You have a database, how can you do backups? How can you do read-only reports? How can you test database restores? There’s quite a bit here and it could all be practiced while the mock client is hitting your app.
- In scenario 1, we had a pool of app servers, what if we wanted to do a major architecture change though? Could we switch databases (mysql to postgres etc) and have our app still run? What about application updates to use that new database type (you’d need to change drivers at the very least)?
- In complicated pools and bouncing connections around, typically HTTP headers are used. Try making an app that reads headers and try bouncing through two load balancers or a load balancer and a reverse proxy server like Nginx. See if the headers survive.
- SSL termination and security around transport. Would need a packet sniffer and some other details to prove and play with this though.
Beyond This
There are many topic areas you could focus on but for the start of this and the bridging of the seam between devs and ops, I have been focusing on a standard three tier app and focusing on problems around uptime. There are probably more pure ops concerns like configuration management, backups, security, patches, vendor hardware and many other things.
For these more pure ops scenarios, I’d probably set up a home lab. You could do this with hardware or cloud but I’d suggest first making a virtual machine network. I’ve only done this with VMWare workstation but you can make a fake network with many VMs (as long as you have like 16gb of memory) and get pretty far with this. This is also a nice way to learn networking basics without buying a switch, cables and a bunch of real machines. How to exactly do this would be a long post and maybe I could do a follow-up. The problem with learning in the cloud is cost. This is probably the most useful environment to learn in though because you’ll learn the cloud concepts instead of (old school) bare metal. VMs will not give you cloud specific experience. If there is any interest in this post, I could try to write up something but this kind of pure cloud/sysadmin job role is getting away from my recent experience.
Wrap Up
I hope this gives you some ideas about practicing scenarios and fighting the catch 22 of ops experience. Most of these examples are about availability and not breaking production. I have broken prod in a variety of ways 😅 and barely seen it coming, so it’s not about being perfect. I think these exercises will give you more intuition and peel back the curtain on processes, database changes, code changes, deploys and some lower level technologies which will not only be very relevant to ops work but also reduce fear and stress when you are in a live scenario.