Tricking Git is Tricking Yourself
I’ve sometimes seen people asking about dependency management, hooks, tracking bugs and other sort of higher level (to me) things than git provides. You can see this if you look at stackoverflow questions about submodules. What’s wrong with submodules? Well, compared to what exactly? When I do a clone of a project and run yarn install, it gives me a list of CVEs that match. When I do a bundle exec it loads my project and has an opportunity (with a very high level of context) to tell me that I’ve forgotten to run migrations or run yarn update in a while. You don’t get this with git. Maybe these examples are too web-tech specific. But I’d like to suggest that this pattern will probably apply to Go, Rust and whatever else. Git is below your project and your project is trying to get better stuff done. So stop trying to solve your problem with Git and listen to how a few other communities do their thing.
I’ll also say that every project is different and as much as I want there to be universal truths, project differences really put some of this stuff into a spin. A lot of this is “to me”. But, I’ve also seen people doing “weird stuff” with Git and when I probe, they haven’t seen or felt success and so they are turning to Git as the tool they already have in place.
Git is really dumb (I mean the cli utility, not the “wrapper frontends” like Github or Gitlab). It’s in the name. It’s in the slogan: “stupid content tracker”. It only really knows how to work with text. You can teach it to understand machine learning binaries and possibly image assets but this is fighting the default. Game developers know this well (I don’t). So it’s interesting when I see other people trying to do it anyway. What I see is a lack of tooling in the language they are using.
Let me give some concrete examples.
- Someone that is trying to do Git tricks for a game project. The answer is go inside your editor (in this case, Unity). They probably continued with git submodules, I’m not sure.
- Someone who was trying to track what code is in what place. They have parallel supported releases apparently. The answer here is probably a spreadsheet, automation software or feature flags (this whole project was a bit of an oddball).
- Someone who is trying to run code automatically on the repo (git hooks). The answer here is CI.
- Someone who wants to share code between projects so they want to use submodules. The answer here might be to look at your language’s packaging and produce a library just like the ones you are consuming from the Internet.
In each case, the details don’t matter too much. Someone is trying to trick Git into doing something. It’s almost like a challenge. “If I can sneak past the guard then I can …”. Just stop for a minute. Listen to other projects and how they are doing it. Explore other languages. You don’t have to learn the whole thing. If you are stuck in Java or C++, learn about Yarn/Cargo/Bundler. Look at what Go went through.
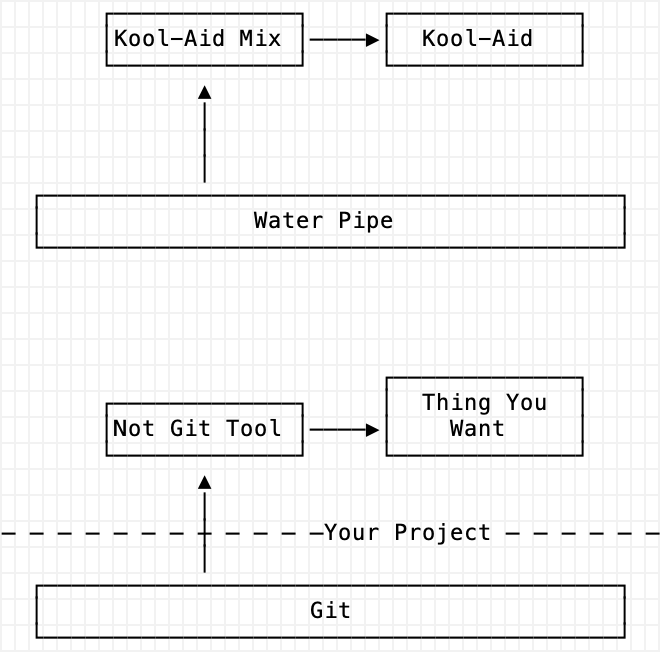
But most of all, move up a level. Instead of hatching a Git plot, move toward your language, your IDE, your framework or your engine. Git is this plumbing bringing you water and you need to add the Kool-Aid packet for your Kool-Aid. It’s so much closer to what you are trying to make.
Let me give you two more examples while sharing a couple of neat tips.
Getting Out of Yarn.lock Hell
You are working on a team and two people modify package.json at the same time. Your project is using yarn. This means the machine generated file yarn.lock is going to conflict. What should you do? Do some git cherry picking wizardry? If we follow our above rules, we will use Git eventually but we want to lean in to higher level tools, in this case yarn.
# dealing with a yarn conflict
git checkout origin/master -- yarn.lock
yarn install
git add yarn.lock
git rebase --continue
We’re keeping our package.json changes but letting yarn do the work of resolving the graph. Easy and it’s higher level than text.
Are We Breaking Anyone?
You have many clients on many versions. You have concurrent support. You want to make a change but you don’t know if you are going to break anyone. Should you create a complex system of tags, SHAs or feature flags? Maybe. But if you want to track where you’ve deployed your code and on what version, you could do this with a spreadsheet (maybe automating later) but what about this particular problem of “did I break someone?”. Using Git, the idea would be something like reacting. You have all these concurrent versions and you want to track each of them so that you can do this whole backporting and parallel support thing (which is expensive).
If you have a web app, you could use contract testing with pact do handle the “can-i-deploy” question (it even has this as a feature). But what if you have a CLI? Well, can’t we see the pattern here? Look beyond Git and see how Pact is approaching the problem. It’s parallel specs and you want to know if your change is going to break anything.
Of these things involved:
- Contract Testing
- Feature Flags
- Tracking Deployments and Customers
- Backporting Code
Only Backporting Code is related to Git and it’s really not that interesting.
Wrap Up
The thing with git is: it’s almost always better to move toward your language tooling. A lot of communities have different values and different strengths. What is obvious in one is not so obvious in another. Tour around a little bit and sample. Bring back what you’ve learned.